
Was ist eine Robots.txt?
Eine robots.txt-Datei teilt Suchmaschinen-Crawlern mit, welche Seiten oder Dateien der Crawler von Ihrer Website anfordern kann oder nicht. Dies wird hauptsächlich verwendet, um eine Überlastung Ihrer Website mit Anfragen zu vermeiden.
Für Webseiten (HTML, PDF oder andere Nicht-Medienformate, die Google lesen kann) kann robots.txt verwendet werden, um den Crawling-Verkehr zu verwalten. Das ist sinnvoll, wenn Sie der Meinung sind, dass Ihr Server von Anforderungen des Crawlers von Google überfordert wird oder um das Crawlen von unwichtigen oder ähnlichen Seiten auf Ihrer Website zu vermeiden.
Wie kann eine Robots.txt erstellt werden?
Die Robots.txt-Datei kann mithilfe eines Texteditors erstellt werden. Zudem ist es möglich, sie über die Google Search Console zu erstellen oder auch zu überprüfen.
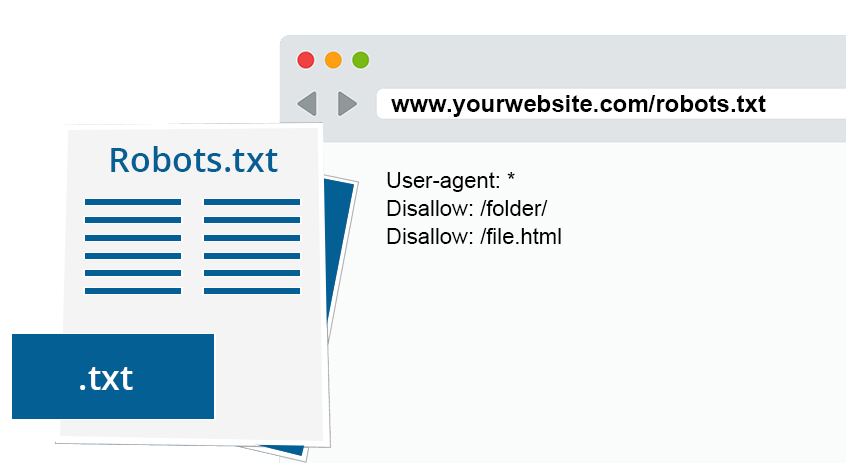
Wichtig ist, wie eine solche Datei aufgebaut ist. Sie besteht nämlich entweder aus zwei oder optional auch aus drei Blöcken. Der erste Block muss dabei immer enthalten, für welche User Agents, also Schnittstellen zum Benutzer, die Befehle des Nutzers entgegennehmen oder Inhalte darstellen, die Anweisungen überhaupt gelten sollen.
Der zweite Block beginnt entweder damit, welche Seiten von der Indexierung auszuschließen sind, also mit „Disallow“, das wäre die zwei-Block-Variante, oder auch mit „Allow“, wonach im Umkehrschluss die einzuschließenden Seiten aufgelistet werden und im dritten Block wieder die „Disallows“ aufzuzählen.
Und wie kann sie dann kontrolliert werden?
Bei Erstellung in der Google Search Engine kann bei „Blockierte URLs“ dann eine Analyse der Datei durchgeführt werden.
Es ist äußerst wichtig, das zu tun, da bei diesen Dateien schon kleinste Fehler im Satzbau dazu führen können, dass Seiten gecrawlt werden, die nicht erwünscht sind. Es ist also von großer Bedeutung, dass eine solche Kontrolle durchgeführt wird, um nicht am gewünschten Ziel vorbeizuschießen und möglicherweise dem Ranking der eigenen Seite in der Google-Suche entgegenzuwirken.
Robots.txt und die Suchmaschinenoptimierung
Für die SEO ist die robots.txt einer Seite äußerst relevant. Von der Datei ausgeschlossene Seiten können nicht mit der Website ranken, was zur Folge hat, dass zu starke Einschränkungen zu einem schlechteren Ranking führen.
Genauigkeit ist also wie bereits erwähnt also von hoher Relevanz bei der Erstellung einer robot.txt-Datei. Wichtig ist auch, dass Befehle in der Datei eine Indexierung nicht verhindern.
Im Allgemeinen ist jedoch zu sagen, dass das zentrale Wesen der robot.txt nicht viel mit der Suchmaschinenoptimierung zu tun hat, sondern vielmehr für eine ideale Nutzbarkeit des Crawl-Budgets sorgt. Die richtige Nutzung der Datei ist also mehr dafür verantwortlich, dass alle wichtigen Bereiche gecrawlt werden und korrekte Inhalte indexiert werden.
Wie werden Seiten konkret ausgeschlossen?
Doch wie sieht der Ausschluss aus dem Crawling für bestimmte Seiten konkret aus? Der reguläre Aufbau wirkt zunächst recht simpel und besteht aus zwei Zeilen.
In der ersten Zeile werden die User-Agents angegeben. Am Anfang der Zeile steht also „User-agent:“. Dahinter muss der User-Agent dann bezeichnet werden, also zum Beispiel „Googlebot“.
Im Code eine Zeile darunter müssen dann die Seiten benannt werden, die ausgeschlossen werden sollen. Also „Disallow:“. Steht dahinter nichts, so bedeutet das, dass keine Seiten von dem Crawling ausgeschlossen werden. Soll gar nichts gecrawlt werden, so muss dahinter ein „/“ stehen. Auf die Sitemap wird, zum Beispiel, mit folgendem Modell verwiesen:
„https://www.immerce.de/sitemapimmerce.xml“Die Web-XML Sitemap ist eine Datei, die die Suchmaschine dabei unterstützt, die Seite richtig zu listen. In unserem Beispiel ist die Domain www.immerce.de und “sitemapimmerce” soll für eben diese Sitemap-Datei stehen. Diese Datei dient also den Suchmaschinen und beinhaltet den Aufbau der Website und auch, wie oft die Seite aktualisiert wird. Es hat also nichts mit dem Nutzerlebnis zu tun.
User-Agents
Wie gesagt muss in der Zeile User-agent der User-Agent eingetragen werden, der betroffen ist, beziehungsweise, für den der Befehl gelten soll. Jedoch können hier auch mehrere User-Agents benannt werden. Soll dies der Fall sein, so erhält jeder Bot eine eigene Zeile. Für die Google Suchmaschine gilt „Googlebot“ für Yahoo „Slurp“, für Bing „binbot“ und für Google-Bildersuche „Googlebot-Image“.
So können die wesentlichen User-Agents angesprochen werden.
Fazit
Die robots.txt-Datei dient der Optimierung des Crawling-Budgets, wodurch Seiten, die unnötig mitgerankt werden würden, einfach ausgeschlossen werden können.
Wichtig ist stets, dass eine Analyse vor Inkrafttreten der Datei durchgeführt wird, um selbstschädigende Fehler zu vermeiden. Zudem kann durch die Datei einer Überlastung an Suchanfragen vorgebeugt werden.